Seismology has always been, at its core, a science of identifying deeply hidden patterns within chaotic noise. For decades, the critical task of identifying the precise onset of a P-wave (compressional) or S-wave (shear) arrival in a continuous streaming waveform was work done almost entirely by experienced human analysts. These analysts were armed with intuition built from thousands of hours of manual waveform review. It was highly accurate, but painfully slow — and inherently impossible to scale across modern regional networks that can easily generate terabytes of raw velocity and acceleration data per day.
The introduction of deep learning has fundamentally and irreversibly changed the economics of phase picking. Massive neural network models like PhaseNet, EQTransformer, and the deeply optimized XiaoNet (my work) variants can now process continuous streams in pseudo real-time, achieving close to human-analyst-level accuracy at a fraction of the computational and human time cost.
The Phase Picking Problem: Why Accuracy is Critical
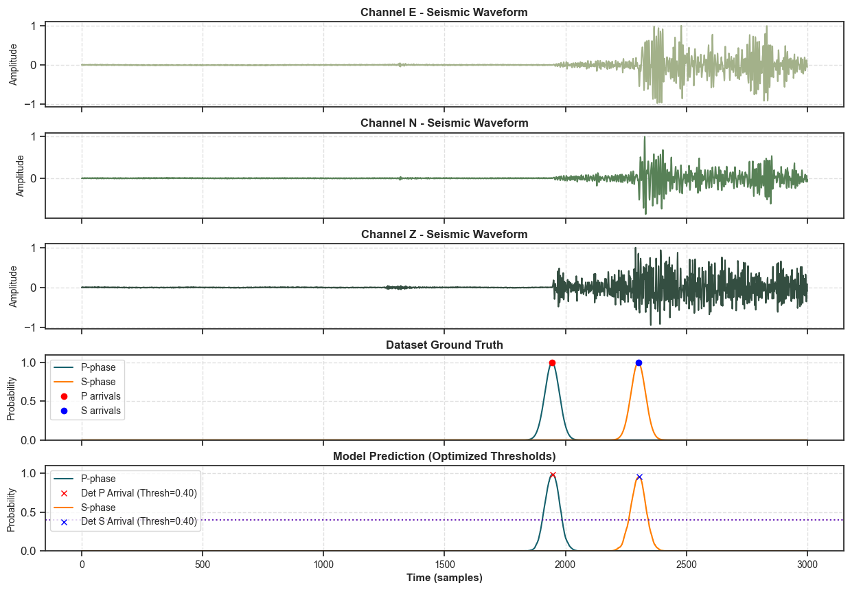
Phase picking is the fundamental task of identifying exactly when a specific seismic wave type arrives at a given station's sensor. The absolute arrival time difference between the faster P-wave and the slower S-wave is used to precisely locate the earthquake hypocenter (the 3D origin) via triangulation across a network of multiple stations.
In seismology, fractions of a second are not rounding errors — they are the difference between a well-located event and a poorly-constrained ghost event. Errors on the order of even 0.1 seconds in an arrival pick can shift calculated hypocenter estimates by several kilometers, drastically altering hazard assessments or fault-plane mapping.
The operational difficulty is that real-world seismograms are incredibly messy. Background seismic noise (from ocean microseisms to local traffic), random instrument artifacts, dropped telemetry packets, and the overlapping coda waves from multiple simultaneous earthquake sources all severely challenge automated systems.
The Legacy of STA/LTA
Before deep learning, the industry standard was the STA/LTA (Short-Term Average / Long-Term Average) trigger algorithm. STA/LTA works by continuously calculating the ratio of the signal amplitude in a short moving window against a longer trailing window. When the ratio spikes past a predefined threshold, an event is declared.
STA/LTA is brilliant in its computational simplicity and handled the easy, high-magnitude cases perfectly. But it struggled aggressively with low signal-to-noise ratio (SNR) microseismicity. It routinely triggered on non-earthquake noise (spikes, passing trains) and often failed entirely to identify the emergent, lower-frequency S-waves that are buried in the P-wave coda.
Deep Architecture: The Seismic U-Net
Modern deep phase pickers abandon the amplitude-ratio approach entirely. They are predominantly U-Net-style encoder-decoder networks operating on raw, three-component waveforms (vertical, north-south, east-west arrays).
The incoming waveform is processed through a series of convolutional encoding layers that mathematically compress the time-series into a dense latent representation, extracting high-level temporal features. The network then expands this representation through decoding layers, utilizing skip connections to preserve high-resolution timing information.
The final output is not a singular binary classification, but rather a continuous probability time series for each specific phase type. The network outputs three continuous streams: P-arrival probability, S-arrival probability, and ambient noise probability. Simple post-processing peak-detection algorithms are then applied to these probability curves to extract the exact, sub-second onset times.
Earthquake Early Warning and Latency
For applications like Earthquake Early Warning (EEW) systems, picking accuracy must be perfectly balanced with extreme latency constraints. Every second spent waiting for more of the waveform to buffer, or spent actively running the neural network inference, is a second subtracted from the warning time given to a city downstream of the epicenter.
This forces engineering compromises. While Bidirectional LSTMs and deeply stacked Transformers often yield slightly higher retrospective accuracy because they can look "forward" into the time-series, they introduce unacceptable buffering latency for real-time EEW. Causal CNN architectures are often preferred in strict real-time pipelines because their latency is strictly deterministic and bound securely to the edge.
The Edge Deployment Challenge
A phase-picking model running comfortably in a central cloud server can leverage massive GPU acceleration and process full 3-component, 100Hz waveforms seamlessly. However, a model deployed directly to the field on an ESP32 or Cortex-M microcontroller works under radically different constraints: fixed-point arithmetic limitations, kilobyte / megabyte scale PSRAM buffers, and no cellular connectivity guarantee.
This is where the TinyML and knowledge-distillation pipelines become critical. By mathematically distilling the massive full-fidelity cloud model into a highly compressed INT8 variant (such as XiaoNet-INT8) that can comfortably handle a sliding buffer window within tight memory boundaries, we achieve a deployable, intelligent seismic detector that runs continuously at the sensor node itself. The node then transmits only highly confident candidate events (as tiny JSON payloads) rather than blindly streaming raw data.
The implication for future monitoring networks is massive: decentralized, AI-native sensor nodes can maintain near-uncompromised detection quality while dramatically reducing the crushing telemetry bandwidth overhead that currently limits large-scale, high-density array deployments.
Be the first to respond.